Exploring Scala 3 Macros: A Toy Quoted Domain Specific Language

I’ve been wanting to learn Scala 3 macros for a while. They seem well supported and documented. However, I could not find a nice learning path. Most guides only provide toy examples of API architecture, but I haven’t found a guide that shows how to build a real macro with the full API.
In this blog post, I present a small project that uses Scala 3 macros. I assume you know about macros and want to see how to use them in actual code that does something other than compute the power function or asserts some assertion. The project is trivial enough that I include all the code in this blog post.
The project
I got some inspiration from the ZIO Quill library. You can use the library to write Scala code that converts to SQL queries for RDBMS. The name of the technique is QDSL (Quoted Domain Specific Language) and was first introduced in a paper by Wadler et al.
The basic premise behind QDSL is to use macros to parse a Scala statement and generate code from it. In the case of Quill, it generates SQL. This approach assumes that the execution of the generated code will be more efficient in the target language.
The benefits of using this approach are:
- Overall, the execution is faster in the target language.
- We get to write our code using all features available in the host language (syntax and type system)
Since this is just a toy example, we will create a simple QDSL to parse CSV files. The target language is the Unix awk tool. An example of the result would be something like this:
// MacroTest.sc
import frontend.Quoted.quote
import frontend.AwkQuery
import scala.quoted._
import backend.ASTCompiler._
case class Data(
code: String,
name: String,
description: String,
quantity: String
)
val q = quote {
AwkQuery[Data].map(x => (x.name, x.quantity)).map(x => (x._2, x._1))
}
println(compile(q.expr))
This code would print something like:
awk '{print $4 }' data.csv
In the first version, we would like to support:
the basic query
quote { EntityQuery[Data] }which we translate to:awk '{print $1,$2,$3,$4 }' data.csvbasic maps
quote { EntityQuery[Data].map(x => (x.name, x.quantity)) }, which we translate to:awk '{print $2,$4 }' data.csvand chained maps
quote { EntityQuery[Data].map(x => (x.name, x.quantity)).map(x => (x._2, x._1)) }, which we translate to:awk '{print $4,$2 }' data.csv
The feature set of the project is not big, but it will take us through most features of the Scala 3 macro system and also through the QDSL technique. This is just a toy example so, do not expect it to cover all the corner cases or gracefully handle errors. We also omit types, we assume that all fields are of type string. The goal is just to understand the mechanics of macros and the QDSL technique.
How to Run the Project
This was my first project using the new scala-cli tool.It greatly simplifies creating and running these posts. To run this project, you need to:
- create all the files with the code listings in one directory, and
- run
scala-cli run .
This will compile it using Scala 3 and run the main script. You can also download the full code from GitHub.
The architecture
Before tackling the architecture, we need to consider that the code we write will run in two different environments. The compiler environment and the application environment. We normally run our Scala applications in the application environment. The thing is that, when we invoke the macro, we will run in the compiler environment. Macros return code, which is compiled and then executed at runtime. This means that, whatever the macro does, it needs to transform its output back to code. This will be important later.
In the quote macro, we need to:
- parse the quoted expression and transform it into an AST (Abstract Syntax Tree)
- normalize the AST
- transform resulting AST back to code, wrapped in a
Quotedtype.
We can compile the AST to the awk command in another macro (to have the full query generated at compile time) or in the application code, to see the output and debug it easily. In our application we will do it in both. One for displaying the actual query as a compile time message and another just to print it to the standard output at runtime. We can see the different steps in the diagram below.
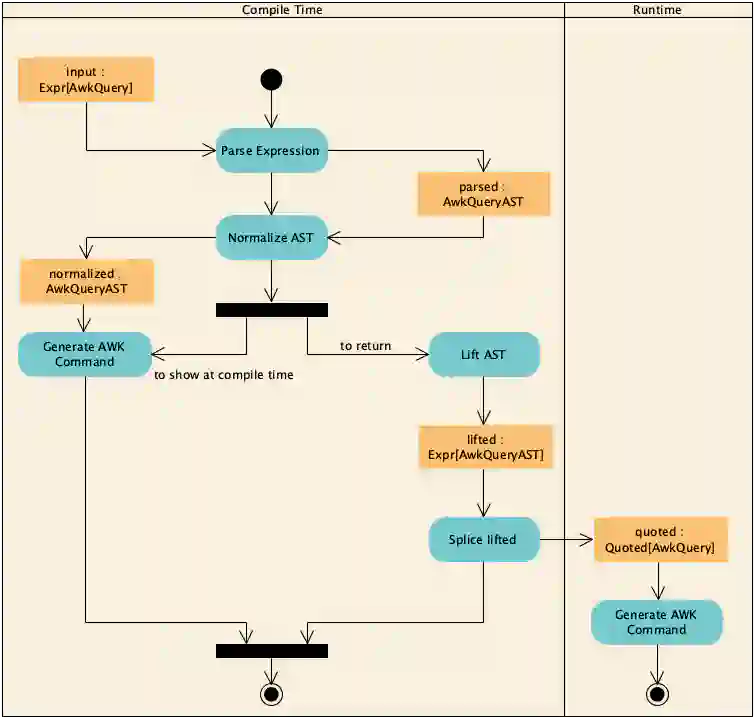
From a structural point of view we have two different layers: the frontend, which are the queries that the user writes or AwkQuery, and the backend, which deals with the AST. The computational heavy lifting happens in the backend, while the macro magic happens mostly in the frontend.
The frontend receives an Expr[AwkQuery] from the user, does some parsing to transform it into something that the backend can understand, the AwkQueryAST . Expr types are the representation of the Scala code. The backend takes that AST, does the necessary processing and hands it back to the frontend for both displaying to the user and returning to the compiler.
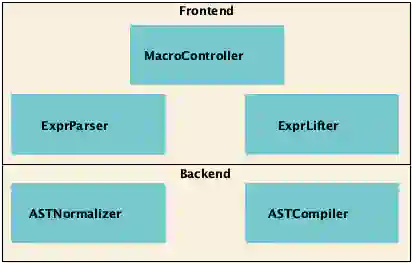
In the frontend component we find the ExprParser, which takes a Expr[AwkQuery] and turns it into a AwkQueryAST. We also find the ExprLifter, which takes a AwkQueryAST and lifts it to an Expr[AwkQueryAST]. This operation is necessary to return the processed AST to the runtime code for further dynamic processing (if desired). Finally, we have the controller, which combines all of the components together.
In the backend we just find the ASTNormalizer and the ASTCompiler. The former transforms the AST to some normal form that is easier to compile1. The latter transforms the AST to the actual text representation in the target language.
The Backend
The backend is completely independent of macros, it works directly on the AwkQueryAST structure. This makes the backend easily testable.
Data Types
The first step is to model the datatypes for the backend. We create the AwkQueryAST as a case class that takes a file and a set of map expressions. Map expressions, for simplicity sake, are just projections. A projection just means that we are taking the string in position n in our input file (which we assume is a CSV table parseable by awk) and show it at the position specified in the projection.
// AwkEdsl.scala
package backend
case class AwkQueryAST(
fileNameOrPath: String,
mapFilterExpr: AwkMapExpr*
)
case class Projection(idx: Int*)
sealed trait AwkMapExpr
case class MapExpr(l: Projection) extends AwkMapExpr
case class CompositeMap(exprs: List[MapExpr])
Components
The ASTNormalizer normalizes the AST given to him to a normal form where only one map expression is present. Indeed, the AST allows to model chained map expressions, but the chained projections can be simplified to just one. Indeed, the ASTCompiler can only translate one simple projection.
As a side note, the paper by Wadler et al. shows that in our processing of the AST we can use features of the host language (for example Option types or Lists) but are not supported by our ASTCompiler. They show that given the right conditions we can always be sure that these extraneous types will be removed.
// ASTNormalizer.scala
package backend
import scala.annotation.tailrec
object ASTNormalizer:
private def expandComposite(
exprs: List[AwkMapExpr]
): List[AwkMapExpr] =
exprs match {
case h :: tail =>
h match {
case CompositeMap(innerExpr) =>
innerExpr ::: exprs
case _ =>
h :: expandComposite(tail)
}
case Nil =>
Nil
}
private def mergeProjections(
exprs: List[AwkMapExpr]
): List[AwkMapExpr] =
exprs match {
case MapExpr(l1) :: MapExpr(l2) :: tail =>
val m1 = Map(l1.idx.zipWithIndex.map(x => ((x._2 + 1) -> x._1)): _*)
MapExpr(
Projection(l2.idx.map(prj => m1(prj)): _*)
) :: tail
case h :: tail =>
h :: mergeProjections(tail)
case Nil =>
Nil
}
@tailrec
private def normalizeList(
exprs: List[AwkMapExpr]
): List[AwkMapExpr] =
val result =
expandComposite.andThen(mergeProjections)(exprs)
if (result != exprs)
normalizeList(result)
else
result
def normalize(awkRootExpr: AwkQueryAST) = AwkQueryAST(
awkRootExpr.fileNameOrPath,
normalizeList(awkRootExpr.mapFilterExpr.toList): _*
)
The ASTCompiler transforms the AST to a string that represents the awk command. After normalization there shoul only be one projection. Compilation is very simple when when only have one projection:
// ASTCompiler.scala
package backend
import backend._
import scala.annotation.tailrec
object ASTCompiler:
def compile(awkRootExpr: AwkQueryAST): String = awkRootExpr match {
case AwkQueryAST(file) =>
"awk '{print $0 }' " + file
case AwkQueryAST(file, MapExpr(expr)) =>
val toPrint = expr.idx.map(x => "$" + x).mkString(",")
s"""awk '{print $toPrint }' $file"""
}
The Frontend
The frontend is where the macro magic happens. It either transforms the Scala code to the AST representation, or transforms the AST representation back to Scala code.
Data Types
The data types for the frontend are defined below.
// AwkQdsl.scala
package frontend
import backend.AwkQueryAST
object AwkQuery:
def apply[T] = new AwkQuery[T]() {}
trait AwkQuery[T]:
def map[R](f: T => R): AwkQuery[R] =
throw new IllegalAccessError()
The AwkQuery type represents the query that the user writes in the QDSL. It is not meant to be run at runtime and thus its method implementations throw an exception. Indeed, what we need of the AwkQuery is the Scala AST, that we will transform into our own AST.
Components
The ExprParser is the workhorse of this macro. In it, we parse the expression and we use the power of the macro API. The entry point is the function parseQuery. It matches the expression using quoted expressions. Quoted expressions let us match expressions roughly and decompose an expression in its parts. For example, we can match that we have a call of the apply method of a given object (our first case in the parseQuery), or we can parse that we have a call to the map method from a given type. However, we cannot capture the call to a method whose name we do not know. To do that, we use the reflect API, which works on terms.
In our case, after getting the map’s argument, we need to parse it. The problem I found when parsing the lambda, is that it is difficult to extract just the body. To extract the body I used a betaReduce. The betaReduce takes a parameter and returns the function’s body with the parameter replaced, ready for evaluation. One problem there, is that I do not care about the parameter being passed, because I am only interested in the body. A solution is to pass a variable with type Nothing. Then we can use the reflect API to decompose the resulting body. The reflect API is much more precise than the quote/splice API. It lets us match the terms not only by structure but also by unknown attributes such as name symbols, that we can later extract.
Once we have the lambda’s body we can use the parseTuples function to extract the tuples inside. We use the quote/splice API to decompose the terms. However, to inspect the tuples and extract the values from the case class and map them the right index we need once again the reflect API. We can see an example of that in the computeIndex function. It matches the terms and extracts the property names that we can then compare to those used in definition of the case class. After doing all of this, we get an AwkQueryAST. A weird thing is that for some reason, the Tuple2 class has 4 case class parameters, and their position does not match what you would expect. The _1 attribute is not the first argument, and the _2 attribute is not the second one. Hence, we need a special case for it. This is probably because of specialization. Let me know in the comments if you know the exact reason for this.
// ExprParser.scala
package frontend
import backend.AwkQueryAST
import backend.AwkMapExpr
import backend.ASTNormalizer
import scala.quoted._
import backend.Projection
import backend.MapExpr
import backend.ASTCompiler
object ExprParser:
def from[T: Type, R: Type](f: Expr[T => R])(using
Quotes
): Expr[T] => Expr[R] =
(x: Expr[T]) => '{ $f($x) }
def computeIndex[T](expr: Expr[_])(using Quotes, Type[T]) =
val quoted = implicitly[Quotes]
import quoted.reflect._
expr.asTerm match {
case Select(Ident(_), propertyName) =>
val tpe = TypeRepr.of[T]
if (tpe.classSymbol.get.name == "Tuple2")
if (propertyName == "_1") 1
else 2
else
tpe.classSymbol.get.caseFields.zipWithIndex
.find(_._1.name == propertyName)
.map(_._2)
.get + 1
case Inlined(_, _, Block(_, Select(Ident(_), propertyName))) =>
val tpe = TypeRepr.of[T]
tpe.classSymbol.get.caseFields.zipWithIndex
.find(_._1.name == propertyName)
.map(_._2)
.get + 1
}
def parseTuples[BaseT](expr: Expr[_])(using Quotes, Type[BaseT]) =
expr match {
case '{
type t1
type t2
Tuple2($v1: `t1`, $v2: `t2`)
} =>
import quotes.reflect.report
import quotes.reflect._
Projection(computeIndex[BaseT](v1), computeIndex[BaseT](v2))
case '{
type t1
type t2
type t3
Tuple3($v1: `t1`, $v2: `t2`, $v3: `t3`)
} =>
import quotes.reflect.report
import quotes.reflect._
Projection(
computeIndex[BaseT](v1),
computeIndex[BaseT](v2),
computeIndex[BaseT](v3)
)
case '{
$v1
} =>
import quotes.reflect.report
import quotes.reflect._
Projection(computeIndex[BaseT](v1))
case e =>
import quotes.reflect.report
report.error("Expression not supported:" + e.show)
???
}
def parseLambda[T, R](using
Quotes,
Type[T],
Type[R]
): PartialFunction[Expr[_], Projection] = { case '{ ((x: T) => $f(x): R) } =>
import quotes.reflect._
val myX: Expr[T] = '{ ??? }
val res = Expr.betaReduce(from(f).apply(myX))
res.asTerm match {
case Inlined(_, _, Block(_, t1)) =>
parseTuples[T](t1.asExpr)
case _: Term =>
import quotes.reflect.report
report.error("Expression not supported")
???
}
}
def parseQuery[T](using
qctx: Quotes
): PartialFunction[Expr[_], AwkQueryAST] = {
import qctx.reflect._
{
case expr @ '{ type t; AwkQuery.apply[`t`] } =>
val tpe = TypeRepr.of[t]
val name: String = tpe.classSymbol.get.name
val proj = Projection(
tpe.classSymbol.get.fieldMembers.zipWithIndex.map(_._2).map(_ + 1): _*
)
AwkQueryAST(name.toLowerCase() + ".csv", MapExpr(proj))
case '{ type qt; type mt; ($q: AwkQuery[`qt`]).map[`mt`]($lambda) } =>
val tpe = TypeRepr.of[qt]
val name: String = tpe.classSymbol.get.name
tpe.classSymbol.get.fieldMembers
val rootQuery = parseQuery(q)
val projection = parseLambda[qt, mt](lambda)
AwkQueryAST(
rootQuery.fileNameOrPath,
(rootQuery.mapFilterExpr :+ MapExpr(projection)): _*
)
case expr: Expr[?] =>
import qctx.reflect.report
import quotes.reflect._
report.error("Expression not supported: " + expr.asTerm)
???
}
}
The other component is the ExpLifter. The lifter is a simple object that transforms compile time instances to Scala ASTs that can be returned to the macro in the code.
// ExprLifter.scala
package frontend
import backend.AwkQueryAST
import backend.AwkMapExpr
import backend.ASTNormalizer
import scala.quoted._
import backend.Projection
import backend.MapExpr
import backend.ASTCompiler
import frontend.ExprParser
object ExprLifter:
def liftMapFilter(
awkRootExpr: AwkMapExpr
)(using Quotes): Expr[AwkMapExpr] =
awkRootExpr match {
case MapExpr(Projection(s: _*)) =>
val ss = Expr(s)
'{
MapExpr(Projection(${ ss }: _*))
}
}
def lift(awkRootExpr: AwkQueryAST)(using Quotes) =
awkRootExpr match {
case AwkQueryAST(fileNameOrPath) =>
'{ AwkQueryAST(${ Expr(fileNameOrPath) }) }
case AwkQueryAST(fileNameOrPath, MapExpr(Projection(s: _*))) =>
val ss = Expr(s)
'{
AwkQueryAST(
${ Expr(fileNameOrPath) },
MapExpr(Projection(${ ss }: _*))
)
}
case AwkQueryAST(fileNameOrPath, mexpr: _*) =>
val res = Expr.ofSeq(mexpr.map(x => liftMapFilter(x)))
'{
AwkQueryAST(
${ Expr(fileNameOrPath) },
${ res }: _*
)
}
}
The lift method uses the quote/splice API to create the Expr instances. The API provides the Expr object to lift primitive types. Using it we can lift the Seq or the Strings.
The final component is the MacroController. The controller is the one who puts everything together.
// MacroController.scala
package frontend
import backend.AwkQueryAST
import backend.AwkMapExpr
import backend.ASTNormalizer
import scala.quoted._
import backend.Projection
import backend.MapExpr
import backend.ASTCompiler
case class Quoted[+T](expr: AwkQueryAST)
object Quoted:
def apply[T](awkRootExpr: AwkQueryAST) = new Quoted[T](awkRootExpr)
inline def quote[T](inline bodyExpr: T): Quoted[T] =
${ MacroController.process[T]('bodyExpr) }
object MacroController:
def process[T](bodyRaw: Expr[T])(using Quotes, Type[T]): Expr[Quoted[T]] =
import quotes.reflect._
val ast = ExprParser.parseQuery(bodyRaw)
import quotes.reflect.report
val normalized = ASTNormalizer.normalize(ast)
report.info(ASTCompiler.compile(normalized))
val liftedQuery = ExprLifter.lift(normalized)
'{ Quoted[T](${ liftedQuery }) }
In the file we also define the actual macro, which is defined with the inline def quote statement. That macro calls the controller which does the actual processing and executes the activity diagram in Fig. 1.
Conclusion
Scala 3 offers a very interesting macro API. As you saw, even the very simple QDSL that we implemented required digging deep into both the quote/splice API and the terms API.
My experience while writing this post was that the term API is not very well documented. I had to search a bit to find the right term to match. Dealing with the lambda was challenging in particular and the solution I found feels like a hack. If you know a better way of extracting the body of the lambda, please let me know in the comments.
If you have read until here and liked this content please consider subscribing to my mailing list. I write regularly about Web3 and Scala.
This normalization step is also used to guarantee that we end up with something that our AST compiler can always handle. ↩︎